🎉恭喜杨学长在CVPR 2025发表高水平论文
📚笨人进行了论文的整理
摘要
在社交媒体中,理解用户的意图与情感面临着独特的挑战,这主要源于多模态数据中固有的不确定性——帖文往往存在信息不完整或模态缺失的情况。尽管这种不确定性真实地反映了现实世界的应用场景,但在计算机视觉领域,尤其是在情感与意图之间内在关联的研究方面,这一问题仍未被充分探索。
为应对上述挑战,本文提出了一个新的数据集:MINE(Multimodal IntentioN and Emotion Understanding in the Wild),该数据集包含两万余条具有特定主题的社交媒体帖文,涵盖文本、图像、视频与音频等模态,且自然呈现出模态的缺失与变化特征。MINE 数据集的独特之处在于,它不仅捕捉了多模态数据中不确定的本质,还揭示了意图与情感之间的隐含联系,并为这两个维度提供了详尽的注释信息。
针对上述问题,本文提出了 BEAR(Bridging Emotion-Intention via Implicit Label Reasoning) 框架。该框架包括两个关键组件:其一是 BEIFormer,用于挖掘和利用情感与意图之间的关联;其二是 Modality Asynchronous Prompt(模态异步提示),用于处理模态不确定性。实验结果表明,BEAR 能够在面对不确定多模态数据时优于现有方法,同时有效挖掘社交媒体内容中的情感与意图关系,提升理解能力。
贡献总结
- 提出 MINE 数据集:首个大规模捕捉意图与情感内在关联的数据集,包含两万余条话题相关帖文,具备自然模态分布,提供精准注释,使得在真实情境下系统性地研究二者关系成为可能。
- 提出 BEAR 框架:一种创新的情感-意图联合理解框架,包含:(i)通过对比学习隐式挖掘情感-意图关系的 BEIFormer;(ii)在不破坏现有特征的前提下处理模态不确定性的 Modality Asynchronous Prompt。
- 建立系统评测基准:在 MINE 数据集上评估多个 baseline 模型,通过大量实验验证 BEAR 在多个指标上显著优于现有方法(例如意图识别提升 +2.65% 的 Macro F1,情感识别准确率提升 +3.54%),从而验证了联合建模情感与意图的重要性。
MINE数据集
介绍
意图(Intention)与情感(Emotion)是塑造人类社会行为与决策过程的核心因素。对于以往的数据集 (MIntRec 和 IEMOCAP 等)他们未能捕捉意图与情感之间的内在关联,也忽视了现实场景中模态不确定性与话题多样性所带来的挑战。解决这些问题对于全面理解自然环境中的意图与情感至关重要。
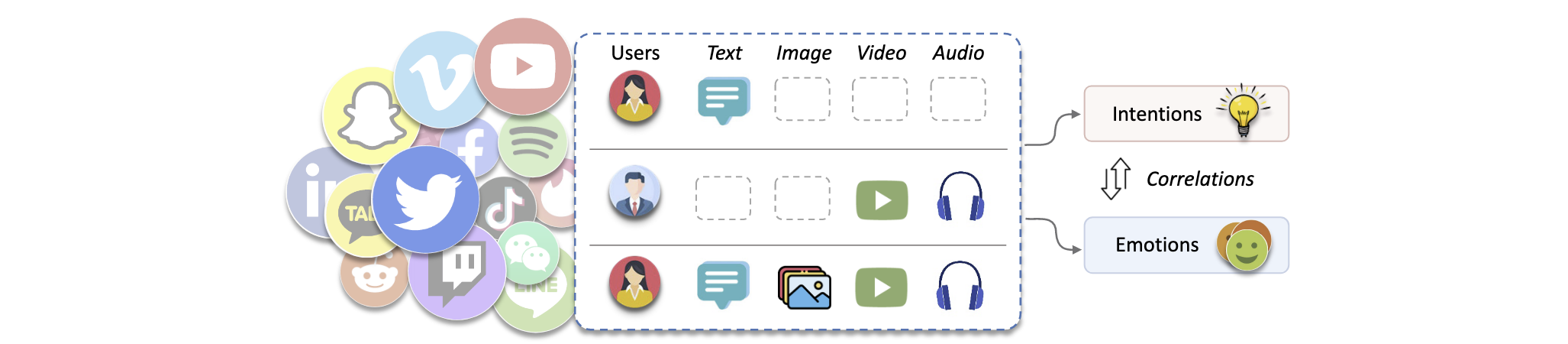
为填补这一空白,本文提出了 MINE(Multimodal Intention and EmotioN Understanding in the Wild) 数据集。MINE 提供了关于意图与情感的详细注释,构建了一个探索其关联关系的平台。该数据集真实地呈现了模态不确定性的挑战,从而映射出现实社交互动的复杂性。该数据集的构建遵循以下几个原则:
- 填补研究空白:MINE 针对现有数据集中缺乏意图与情感交互建模的问题,提供了在社交语境下全面洞察这两者关系的可能。
- 现实性与真实性:与那些在受控环境下生成的数据(如剧本化对话或电视剧片段)相比,这类数据通常与现实场景存在较大差异,而 MINE 基于社交平台上的真实用户生成内容构建,更加贴近现实中意图与情感的表达方式。
- 模态不确定性建模:不同于通常假设模态固定的数据集,MINE 引入了社交媒体中模态缺失的挑战,使得意图与情感理解任务更具现实性和实用性。在算法层面,这体现为“模态缺失问题”(missing modality),即不同样本之间模态组合的异质性。以往关于模态缺失的研究通常依赖于随机采样来模拟模态缺失,这种方式可能引入偏差与噪声。而 MINE 保留了原生的模态信息,避免了潜在错误,为模态不确定性研究提供了可靠的基准。
- 话题上下文增强:MINE 还利用社交媒体中的话题标签(如 #CAMPUS)作为客观语境,为在特定语义框架下分析意图与情感提供了支持,从而促进对两者更为细致入微的理解。
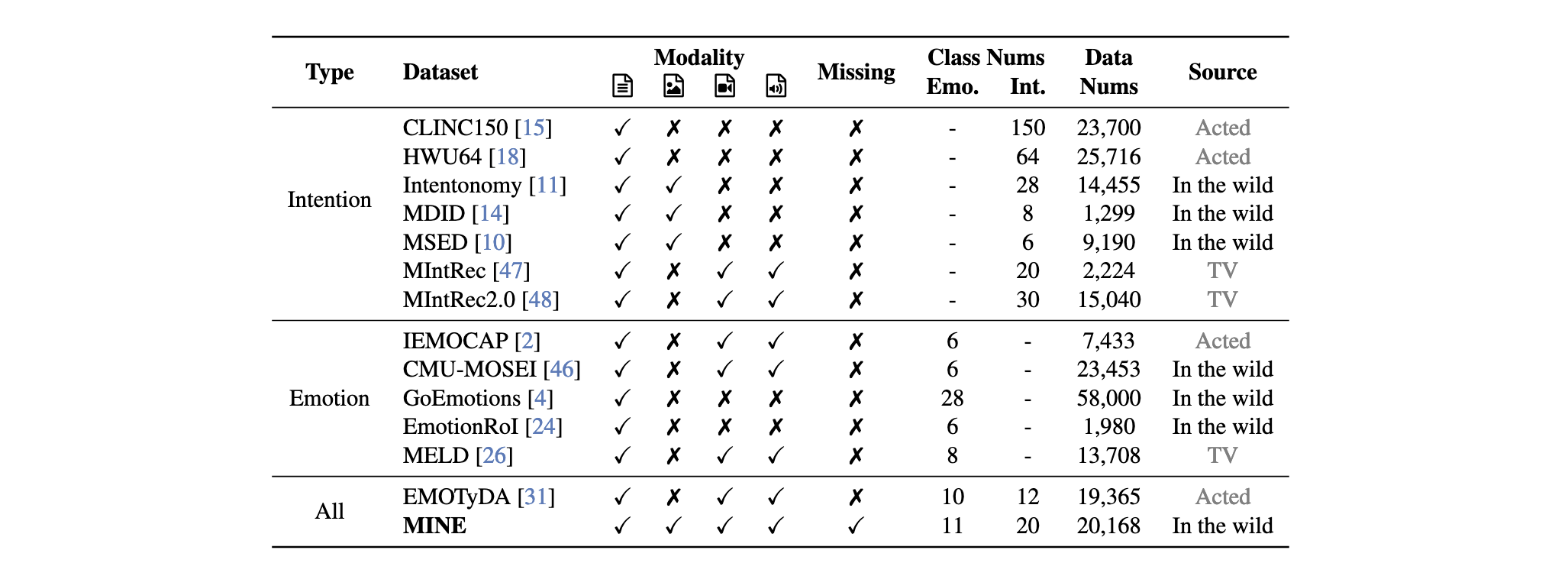
可以看到,与现有数据集中关于意图、情感及其联合理解的对比分析表明,MINE 是唯一一个在真实世界场景中同时结合情感与意图分析,并针对模态不确定性问题进行建模的数据集。
构建
为了探究在现实场景中话题如何影响人们对意图与情感的理解,本文在获得数据主体授权同意的前提下,从社交媒体平台收集了高质量的多模态数据。这些平台聚集了丰富真实的用户表达,极大区别于实验室环境中的人造数据限制,或是以往研究中常见的如电影片段这类数据源所带来的话题多样性不足问题。
本文的策略是基于话题标签(hashtags)对多模态数据进行聚类整理,以确保数据来源的丰富性与多样性。MINE 数据集全面覆盖了十个与日常生活密切相关的核心话题。MINE 在这些话题上进行了深入探索,并特别关注通过相关关键词识别出的交叉领域。(例如,关键词 “Education(教育)” 涵盖的子话题包括“社交媒体对师生的影响”与“社交媒体在学术学习中的应用”。)
数据收集涵盖 2019 至 2022 年间的 Twitter 帖文,用官方API获取。为保证数据质量,本文采用了多重预处理流程,包括剔除无意义文本(如纯链接或乱码)以及过滤敏感内容。虽然视觉内容在传达意图与情感方面起着关键作用,但本文也刻意保持文本模态的比例,以实现更全面的多模态分析。最终的数据集中,视觉内容约占总量的 70%,构成了一个多样但不均衡的模态分布。
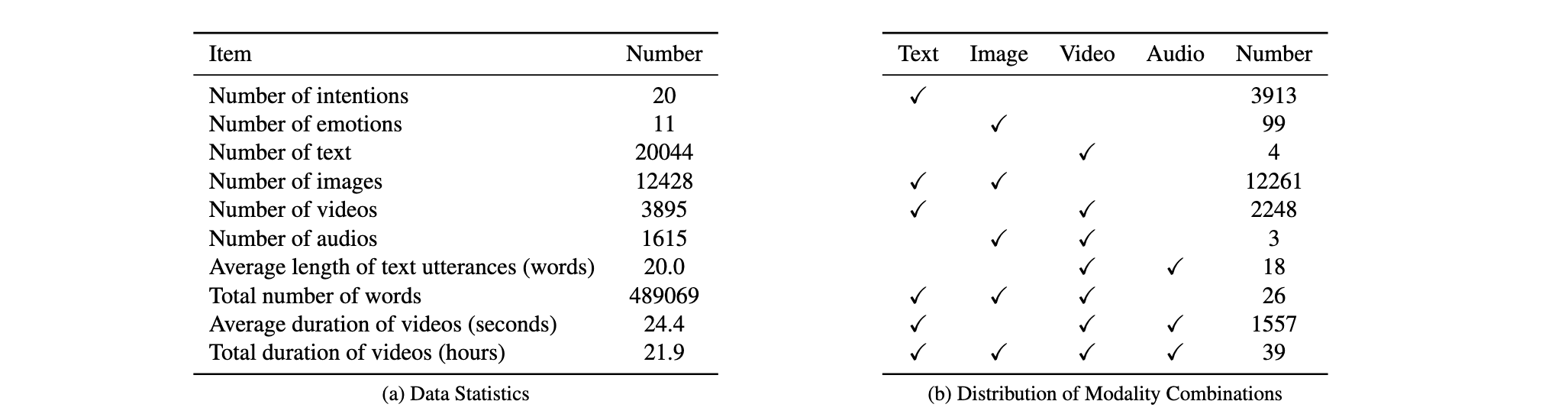
MINE 为每条数据提供了 20 个意图标签和 11 个情感标签,本文将意图识别建模为 多标签任务(multi-label),以捕捉社交媒体互动的细致语义;而情感识别则建模为 单 标签任务(single-label),用于识别主要情绪状态。
整个标注工作由两组独立标注者完成(分别为 15 人与 13 人),并在领域专家的监督下进行。通过多轮训练与校验,初期超过 25% 的标注差异被逐步降低至不足 3%。最终数据集包含 16,000 条训练样本,2,000 条验证样本,2,000 条测试样本,其中 20% 样本经过专家额外审核。
对标注结果的分析显示,意图与情感之间存在强关联关系。例如,攻击性意图(如“批评”“反对”)常与负面情绪共现;而“安慰”类意图则常伴随“悲伤”情绪,表明其情感支持的意图作用。此外,本文还观察到部分话题与意图之间存在一一对应关系(如“教育”类内容中常出现“教学”意图),但这种对应关系远不如意图与情感之间的联系紧密。
为了便于后续的多模态融合分析,本文对每种模态(文本、图像、视频与音频)均进行了预特征提取。这种方法带来三方面的好处:
- 降低信号复杂度与计算成本,便于研究者使用;
- 实现多模态融合技术之间的统一与公平比较;
- 降低与原始数据相关的隐私风险。
在特征提取过程中,本文使用了当前最先进的预训练模型:文本使用 BERT ,图像使用 ViT-S ,视频使用 Video Swin Transformer ,音频使用 wav2vec 2.0 。所有模态提取的特征维度均统一为 768,以便进行一致的多模态融合。
BEAR框架
BEIFormer模型
意图与情感之间的相互关联在现实生活情境与神经网络建模中都具有重要意义。现有的方法通常只关注意图或情感其中之一,往往忽略了二者交互所蕴含的重要信息,从而限制了对这两个维度的全面理解。为弥合这一研究空白,本文提出了 BEIFormer(Bridging Emotion-Intention Former) 模型,该模型旨在统一处理意图与情感这两个关键维度。
具体而言,本文首先基于多模态数据建立情感与意图理解的基础流程,即对多模态数据进行预特征提取,分别生成文本模态、视觉模态与音频模态的特征表示。随后,本文引入Multi-modal Transformer模块,用于聚合任意两种模态的信息并提取其联合特征。
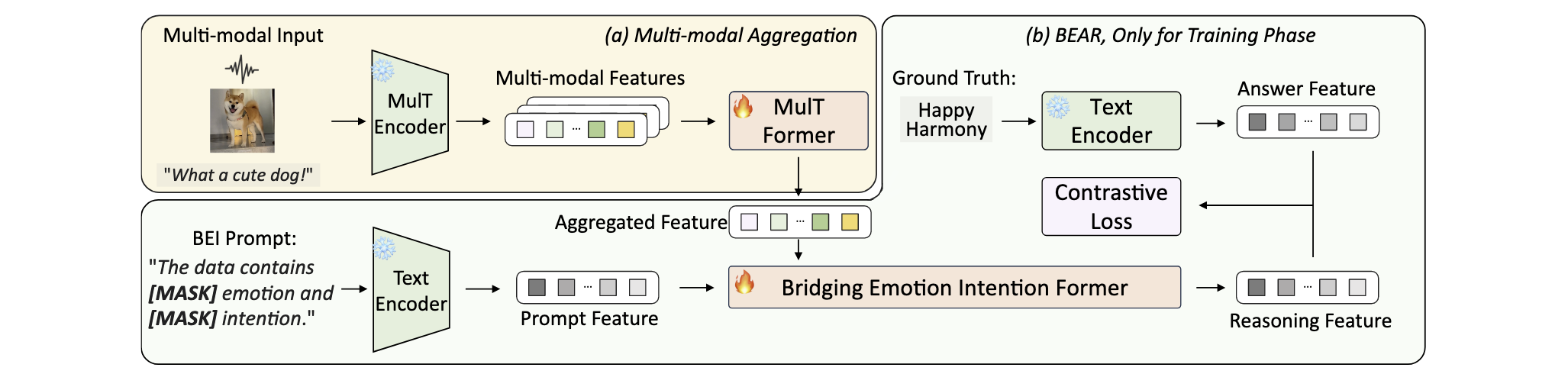
在对三种模态应用“两两跨模态适配(two-pair cross-modal adaptation)”后,本文情感或意图相关的单一目标特征**,未能充分挖掘两者之间的内在联系,而这种联系本可以作为额外的监督信号提升模型表现。
为利用这一潜在的关系信息,本文设计了隐式 BEIFormer(implicit BEIFormer),通过整合 Multi-modal Former 中各层的中间 token 表征,建立情感与意图之间的隐式关联,以加强模型对这两个主观维度的理解。具体而言,本文定义了一个 BEI 提示(BEI Prompt),其作为一种文本模态的先验结构,其中使用 [MASK] token 对与情感-意图相关的先验信息进行“遮盖”。随后,本文通过 BEI Former(一个基于 Transformer 的子网络)处理该提示,生成提示特征,作为 BEIFormer 的 Query 输入。
而 模态聚合表示则被用作 BEIFormer 的 Key 和 Value 输入。通过这种方式,BEIFormer 能够输出最终的交互特征,用于捕捉多模态中隐含的情感-意图交互。
接下来,本文将情感与意图的标签转化为文本信息,并使用文本编码器将其嵌入到与提示特征相同的表示空间中,得到真实标签特征。训练过程中,本文将与 BEIFormer 输出的交互特征进行 对比学习(contrastive learning),以强化模型对情感-意图关系的理解与对齐能力。
本文使用的对比损失函数定义如下(温度超参数经验上设定为 0.05)
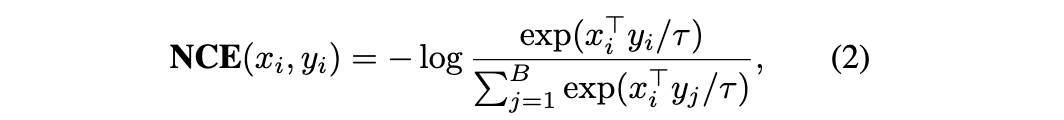
完整的训练损失函数定义如下:
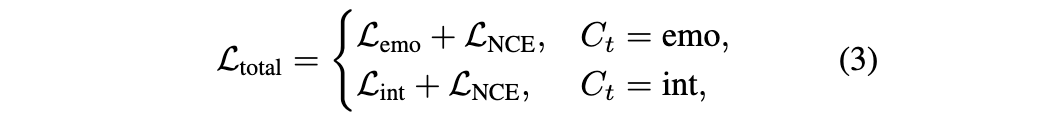
其中,对于情感识别任务,本文采用标准的多类交叉熵损失函数:
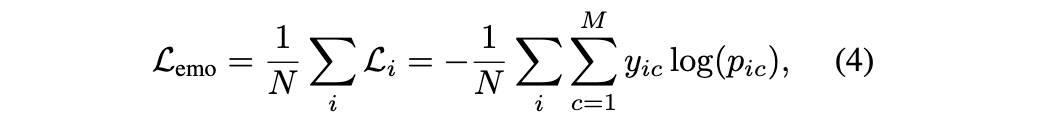
MAP机制
除了情感与意图之间的交互关系外,模态不确定性(modality uncertainty)所带来的挑战也是多模态理解中亟待解决的重要问题。然而,现有方法普遍未能提供有效的解决方案。例如,MMIN 试图在多模态训练阶段学习模态之间的相关性,以便在推理阶段根据已知模态推断出缺失模态的信息。然而,这种策略高度依赖于丰富的多模态先验知识,而这种前提在社交媒体等现实场景中往往难以满足。相比之下,一些方法如 MPMM采用了另一种策略,通过引入提示(prompts)机制将缺失信息融入神经网络。然而,它们通常不加区分地将所有模态拼接在一起,这可能破坏模态特征的结构完整性,导致语义扭曲,从而降低模型在处理缺失模态时的有效性。
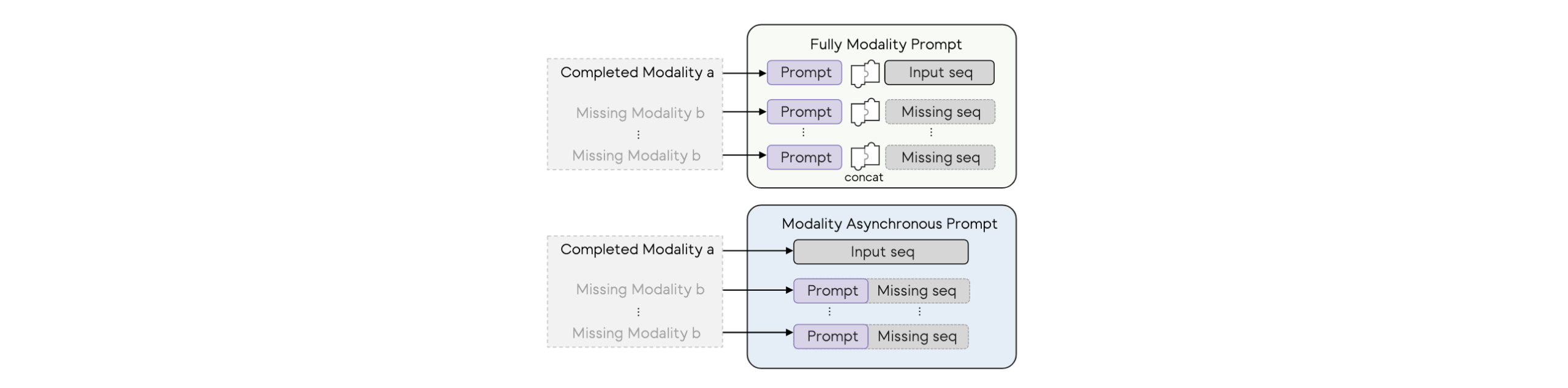
为应对上述问题,本文提出了 Modality Asynchronous Prompt(MAP)机制。该机制可针对不同类型的缺失模态动态地提供异步提示(asynchronous cues)。对于每一种缺失模态组合,本文设计了一组特定的提示,用于提供与语境相关的补充线索,在增强缺失模态语义的同时,保持现有模态的特征不被干扰。例如,当文本与图像模态缺失时,本文的方法仅对缺失模态进行补充和引导,而不影响音频模态的原始表达。
此外,在特征融合方式上,本文不采用拼接方式,而是通过Element-wise addition将提示特征与缺失模态的特征相结合,从而有效避免引入额外的多层感知机(MLP)结构,减少参数量与计算开销。
实验与结果
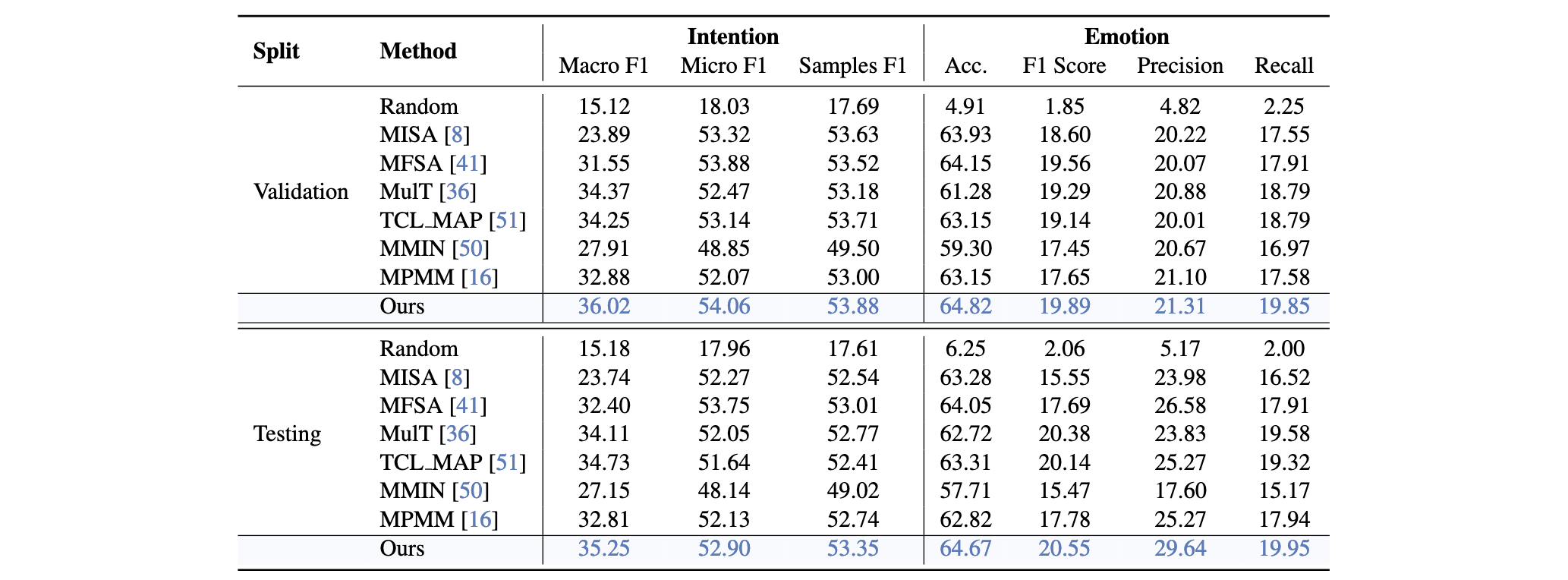
该图表展示了不同方法在意图与情感理解任务上的性能对比。本文的方法在验证集与测试集上均显著优于现有方法,体现了其在应对模态缺失和挖掘情感-意图关系方面的优势。
在验证集上,本文的方法在意图识别任务中取得了 36.02% 的 Macro F1 分数,相较于 MulT 基线提升了 2.65%;在情感识别任务中,准确率达到 64.82%,超过 MulT 3.54%。在测试集上,性能提升仍然保持一致:本文的方法在意图识别上取得 35.79% Macro F1,情感识别上达到 64.53% 准确率,分别比基线高出 2.68% 和 1.81%。
这些结果突出表明了本文提出的 BEAR(Bridging Emotion-Intention via Implicit Label Reasoning) 框架的有效性。BEAR 显著提升了意图与情感识别的准确性,较之于将二者分开处理的传统方法,在多项指标上均实现了实质性提升。
综上所述,本文的方法不仅展现出在多模态数据分析中的优越性能,也验证了其在社交媒体语境下对主观信息(如意图与情感)进行深入、准确理解的能力。

同时,本文对 Modality Asynchronous Prompt(MAP) 与 Bridging Emotion-Intention Former(BEIF) 的组合优势进行了深入分析,详见表 4。实验结果表明,虽然每个组件单独使用时均可带来性能提升(例如:MAP 将意图理解的 Macro F1 提升至 33.36%,BEIF 提升至 35.25%),但将两者结合使用才能显著增强模型效果:最终获得 35.79% 的 Macro F1、53.92% 的 Micro F1 和 54.88% 的 Samples F1。
特别值得一提的是,MAP 的消融实验突出展示了本文方法在应对缺失模态问题上的有效性。MAP 提出的异步提示机制能够补充缺失模态的信息,同时不会破坏现有模态的特征空间。此外,采用 Element-wise addition 代替传统的拼接方式,有效保证了特征维度的一致性与表示结构的完整性。
这些结果表明,本文提出的整体性方法能够在处理复杂多模态数据时提供更细致、全面的理解能力。
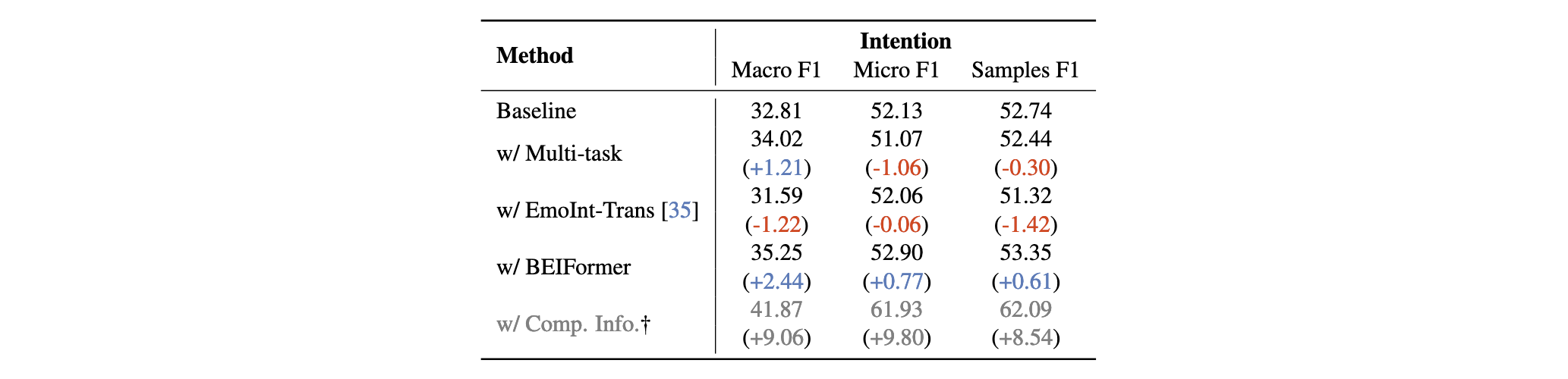
为了验证不同策略在挖掘情感与意图关系方面的有效性,本文设计了一组消融实验。实验包括多种对比方法:
- 首先是传统的 多任务学习(multi-task learning)范式,该方法直接将情感与意图的损失函数进行简单叠加。虽然该方法结构上简洁,但因缺乏专门用于建模情感-意图关系的机制,其提升有限(Macro F1 仅提升 +1.21%)。在某些场景下,该策略甚至会削弱意图理解能力,如 Micro F1 下降 1.06%、Samples F1 下降 0.30%。
- 其次是 Complete Information(Comp. Info.) 方法,它在训练和推理阶段都使用其中一类标签(如情感)作为先验进行引导。该方法在性能上取得了较大提升(Macro F1 +9.06%、Micro F1 +9.80%),但其实际应用受限于现实中先验知识的可获取性,不具备普遍适用性。
相比之下,本文提出的 BEAR 框架 不依赖于额外的推理阶段信息,且在所有指标上都实现了稳定的提升(例如 Macro F1 提高 +2.44%),进一步凸显了其在情感-意图联合建模中的有效性与实用性。
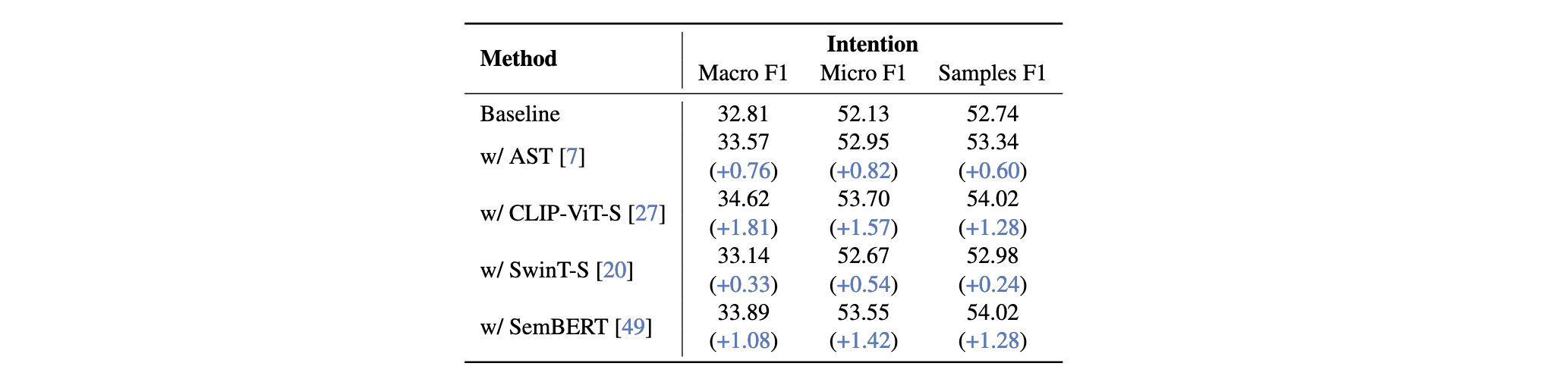
除了模型架构本身,本文不同模态特征提取器**对意图与情感理解性能的影响。本文评估了多种当前最先进的特征提取器,分别对应视觉模态、音频模态和文本模态。
如图,更先进的特征提取器能够持续提升模型性能。其中:
- CLIP-ViT-S [27] 在视觉模态上的引入带来了最显著的性能提升(Macro F1 提高 1.81%);
- SemBERT [49] 在文本表示方面表现优异,提升 Micro F1 1.42%;
- AST 虽然在指标上的提升较为温和(Macro F1 提升 0.76%),但考虑到音频模态在测试集中所占比例较小,其实际贡献被低估,影响实质上更为显著。
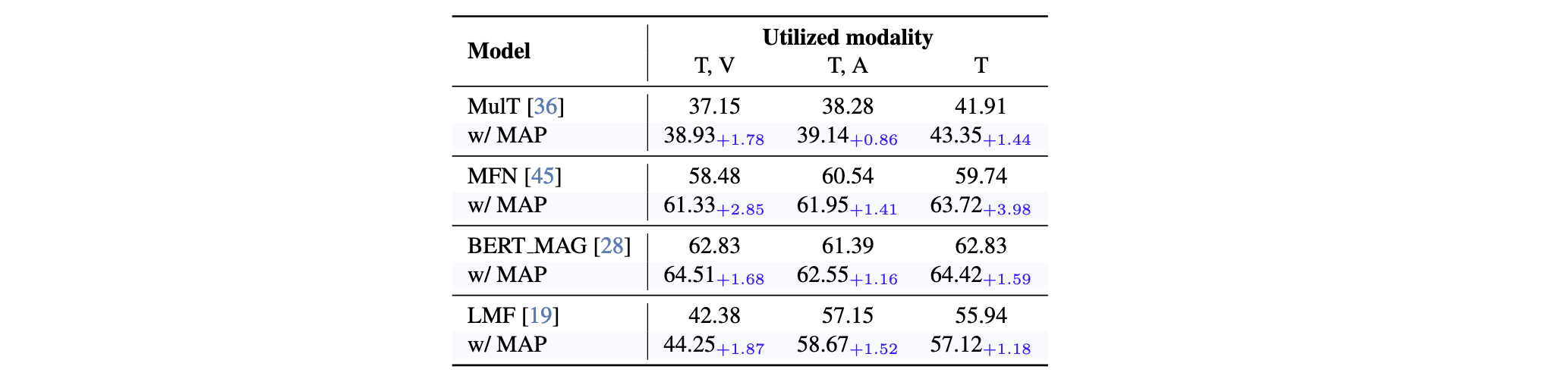
为了验证本文提出的 MAP 方法的泛化能力,本文在 CMU-MOSEI 数据集上进行了实验,涵盖多种基线架构,具体结果见表 7。实验表明,MAP 在所有测试配置下均实现了稳定的性能提升,无论是在不同网络结构,还是在不同模态组合下均表现出一致的优势。这些结果充分验证了 MAP 在处理模态缺失问题方面的鲁棒性与泛化能力。

除此之外,值得注意的是MINE 数据集中的模态不均衡是有意设计的,旨在模拟社交媒体内容中自然发生的真实世界模态分布。 为评估模态不均衡对模型性能的影响,本文进行了模态重采样实验(modality resampling)。通过对稀缺模态进行 2 倍或 3 倍的重采样,特别是采用 特征层重加权策略(feature-level contribution resampling),模型的理解性能得到了进一步提升。
总结
本文提出了 MINE,一个新颖的数据集,旨在捕捉社交媒体自然环境中意图与情感之间的内在关联。与现有数据集普遍将两者割裂处理,或依赖受控环境采集不同,MINE 保留了真实社交媒体数据中固有的挑战,特别是模态不确定性与话题多样性。MINE 为多个模态维度提供了详尽的意图与情感标注,建立了一个系统性基准,有助于在自然场景下深入理解人类社会行为。
为有效处理 MINE 中复杂的多模态数据,本文提出了 BEAR(Bridging Emotion-Intention via Implicit Label Reasoning) 框架,该方法聚焦于两个核心挑战:情感与意图之间的内在关系,以及模态不确定性。BEAR 通过一个基于掩码的标签对齐任务,对情感与意图进行隐式联合建模;同时,提出的 Modality Asynchronous Prompt(MAP) 针对缺失模态进行定向引导,有效保留已有模态的特征完整性。实验结果表明,BEAR 在多个评估指标上均优于现有方法,验证了其有效性。
总之,MINE 数据集为通过多模态内容理解人类社会行为开辟了新的研究路径,而 BEAR 框架为应对现实中复杂多模态场景提供了强有力的技术支撑。