🎉 经典的双塔结构 Learning Transferable Visual Models From Natural Language Supervision
作者单位
OpenAi
论文背景和研究问题
之前的图片分类网络只能对于固定的类别进行分类(ImageNet Cifar10 Cifar100等),这严重缺乏泛化性,而且需要根据类别来人工标注label。所以,找到一个不需要对数据进行标注就能训练,且不需要事先固定好分类类别的视觉模型是很重要的。
这篇文章的作者收到NLP领域Transformer的启发(BERT和GPT都是自监督训练,不需要提前标注),想到用自监督学习用在图像分类领域来得到一个不需要提前标注的视觉模型。
论文动机和贡献解读
该文通过将自监督学习利用在图像分类领域,找到了一个不需要对数据进行提前标注,就能对不定类别的进行分类的可迁移视觉模型。并研究了它相对于传统CNN的性能优势。
方案设计分析
该文的训练任务,是一个图片和文本配对的任务。文本通过一个Text Encoder,图像通过一个Image Encoder,最终得到两者的向量表示,再取其点乘。然后,在这个空间中,拉近配对图文对的距离,疏远非配对文本对的距离。
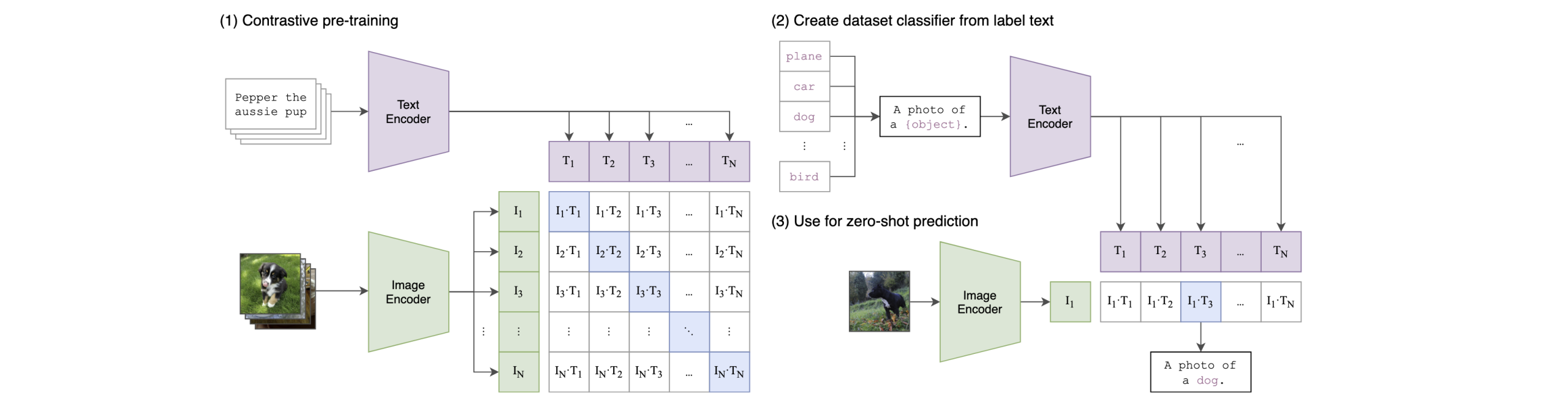
训练结束后,就可以进行推理了。文章中的方法是先按照这样的模式:“A photo of a (name of the object)”组织语句(原文中的实验指出,这样的Prompt可以使accuracy在ImageNet上的精度提升1.3%),得到n个类别的文本向量,再放入Text Encoder中进行embedding;图像则经过图像编码器进行编码,之后计算余弦相似度,哪个相似度最大,就输出哪个编码。
实验效果
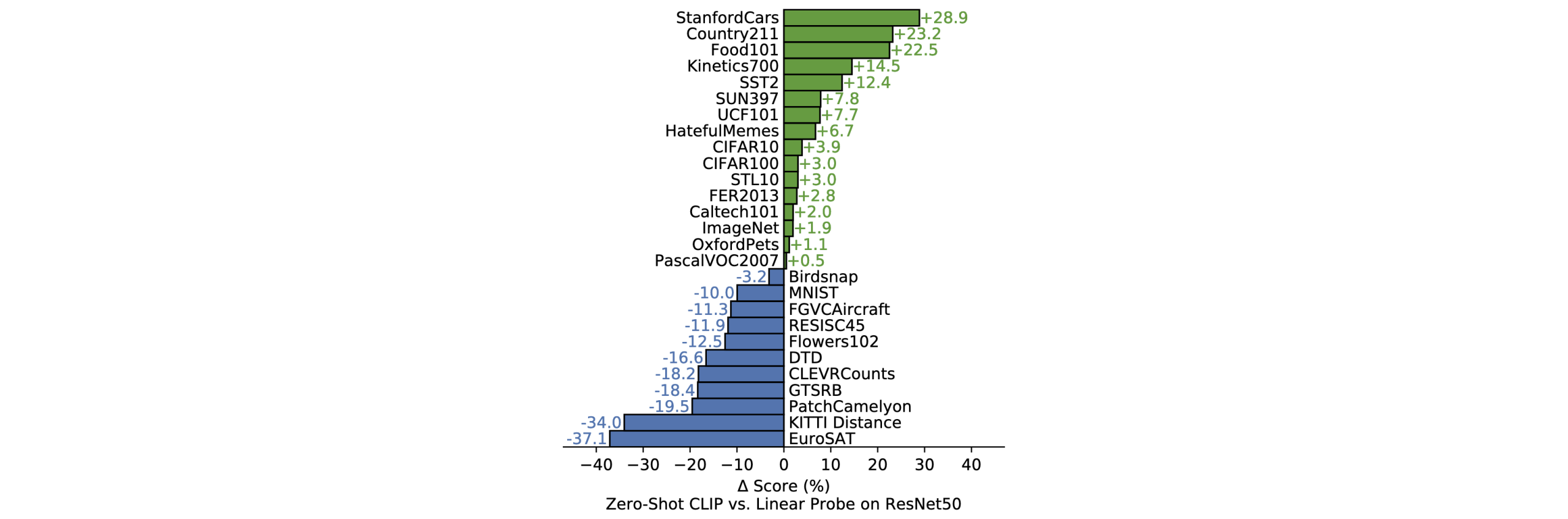
CLIP在自己4亿图文对训练后,不在其他数据集上做任何训练,直接进行zero-shot预测。再对比在ImageNet上预训练的ResNet50(这对ResNet50肯定有更大的优势,因为他可以在这些数据上做微调)
结果可以看到,在大部分数据集上,都是CLIP领先。
那么如果在CLIP图片encoder也加入分类头作微调呢,可以看到不论是每个类别1个例子,2个例子,4个例子,8个例子,都是CLIP领先。

为了进一步证明CLIP的泛化能力,作者给了个更加有说服力的例子,可以看到,在泛化的数据集(例如素描,卡通风格)等等,ResNet的性能大幅下降,而CLIP仍然坚挺(可以看到CLIP具有非常优秀 的泛化性能):

实验结论
该篇论文证明了CLIP模型强大的泛化能力,和优秀的性能表现(相较于传统的神经网络架构)。 其使用丰富的语意进行监督,使模型能够学习到更多的细节语意特征。 连接视觉和文本两个modality,可以引用文本来查询图像。 且不需要预先定义固定类别的标签,直接用prompt进行查询操作。
理解
该篇论文的创新点在于,抛弃了原有的data+label的结构,而应用类似于对比学习的概念,没有具体的类别,只需要规定哪些是positive的,哪些是negative的,用infoNCE为损失函数,拉近positive的距离,疏远negative的距离。(本文中则是,对应的图文对为positive样本,相反的图文对为negative样本)
参考文献
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021.