入门综述
多模态是一个融合性的领域,其本质是处理heterogeneous的Data,将不同的modalities(e.g. Vision, Acoustic, Touch, Language)放到一起进行融合训练。(不同Modalities会在元素种类,分布,数据结构,涵盖信息的丰度,噪声等级,与task的相关度等方面有区别[1])。

根据最经典的综述论文[2],融合训练的方式可以分为以下几种类型:
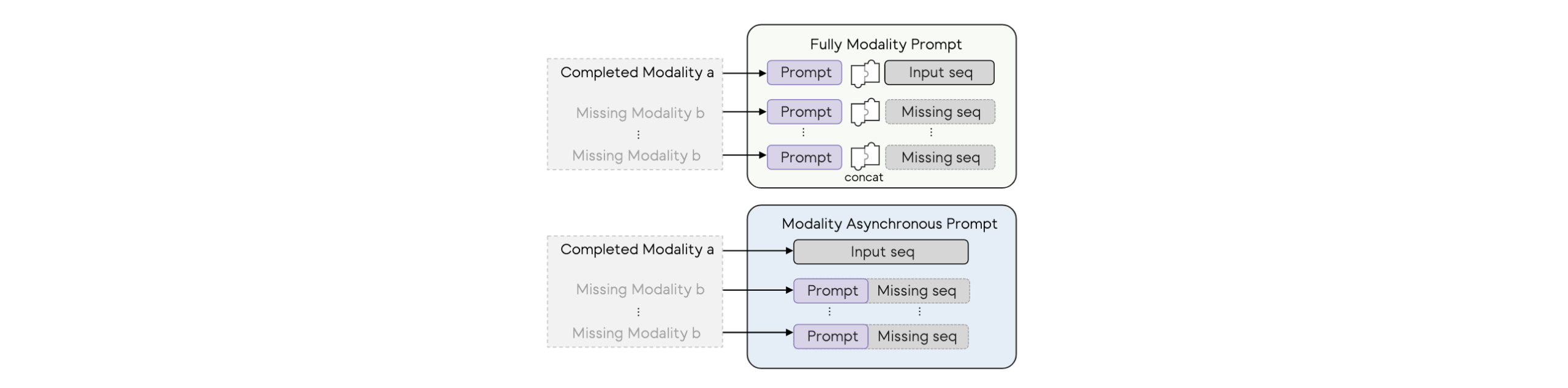
- Early Fusion:在data输入的时候就进行结合(e.g.图像像素信息和文本都映射到一个空间,即将文本和图像特征直接拼接)
- Mid Fusion:在中间层进行交互[3][4][5](e.g. 利用Transformer机制,在 Transformer 的中间层进行 cross-attention 或融合[3];CLIP模型,双塔结构,对比损失优化,使图文两者分别的编码器在一个空间里进行优化对齐[4] )
- Late Fusion:不同modality的模型独立的进行输入,计算,和得出结果,在最后通过投票或者加权平均等方式得到结果。
其中,在2018年以前,Early Fusion和Late Fusion占据主流地位,但是在此之后Mid Fusion(拥抱transformer机制)逐渐成为主流方法[1]。
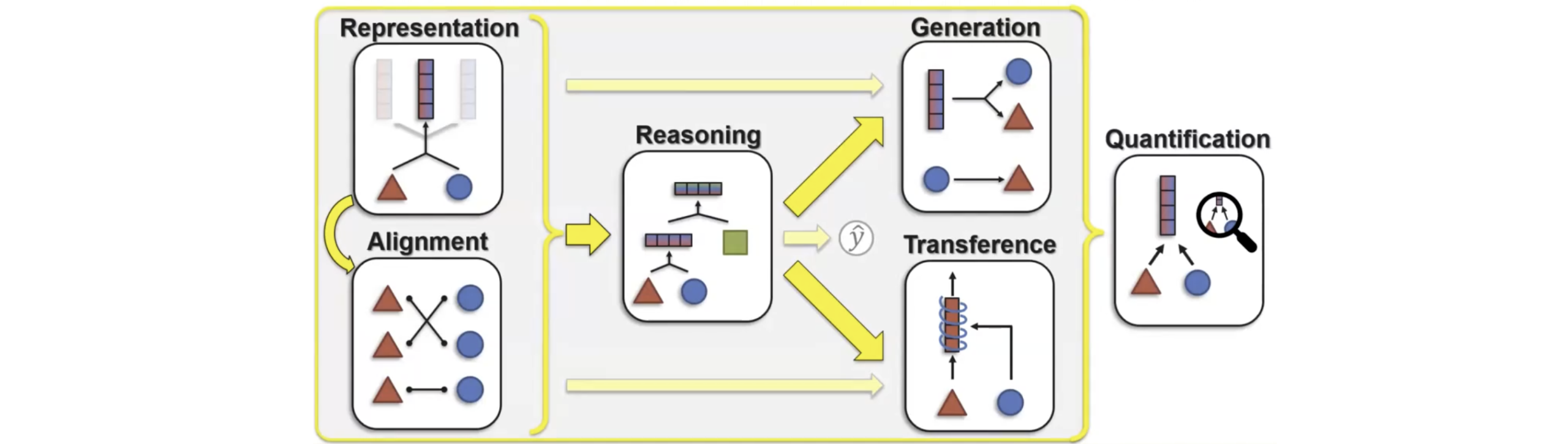
同时呢,这篇文章[1]也从宏观的角度讲解了目前多模态所面临的一些挑战和方向:
- Presentation:即对于元素的表示,这种表示可以是“局部”的,也可以是融合两个元素的“整体”表示。 总的来说可分为三类:Fusion(即用融合的表示去表示不同的modality),Coordination(即对不同表示之间进行对齐),Fission(即创造一种新的表示,可以是一种新的modality)

- Alignment:即研究不同的modality是如何连接的(例如图文转换中,特定的文字和特定的图片之间的连接,这里不难看出,Alignment不是一对一关系,而是可能一对多,多对多,比如一个文字可以由多个图像来表示)在本文中,作者将它分为了三种类型:discrete alignment(对离散数据进行对齐),continuous alighment(即对连续的数据进行对齐,这更多是加权关系),contextualized representations(即通过捕捉元素之间的跨模态交互来得到更好的训练效果)

- Resoning:在多模态训练中,往往需要通过多个步骤,来融入不同modality的知识和数据(甚至在有的情况下加入一些External Knowledge来提升model性能)。

- Generation:即训练一种生成过程,以此生产一些新的modality,由源信息和生成信息的多寡可分为Summarization, Translation, Creation:

- Transfer:即在不同的modalities之间传递knowledge,一般来说是为了帮助一些训练数据资源有限或者noisier的modality获得更好的表现。(e.g. 在上古时代的研究中(2018年之前)人们一直尝试将CV领域的model中的Knowledge传递到语言模型中,但在如今这个时代,由于大语言模型中有巨量的信息,所以最近的研究基本上着眼于将LLM的信息传递到其他model中[1])

- Quantification:即量化,通过量化,我们不去追求better accuracy,而是在量化后的训练和研究中能够更好的理解Multimodal的本质
这里我已经从宏观角度阐述了多模态这个领域,接下来我会谈一谈我对于细分领域——多模态的垂域应用微调——的理解。
对于一个已经训练好的上游模型,在进行实际工程落地的时候会进行微调,但是普遍上,上游模型微调存在以下问题[6]:
- Task-Expert Specialization :当目标的数据集和预先训练的数据集在分布上有较大差异的时候,MLLM模型性能将受到限制。
- Open-World Stabilization : 即模型在下游调优的时候可能会面临灾难性的遗忘,从而丢失预训练时获得的通用知识。为了解决这些问题,调优范式可以被总结成三种[6]:
- Selective Tuning:即分辨出与下游任务相关的参数是哪些,仅仅调整这部分参数,保持其他参数不变。(e.g. SPIDER方法,通过PID动态选择关键参数进行更新[7])
- Additive Tuning:即固定已有的参数和层不动,添加一些可训练模块仅仅去优化和调整附加的部分。
- Reparameterization Tuning:将权重矩阵分解为低秩矩阵的乘积,仅仅更新低秩分量,来防止全局遗忘和模型性能下降(e.g. LoraSculpt框架[8])。
参考文献
[1]Liang, Paul Pu, Amir Zadeh, and Louis-Philippe Morency. “Foundations and trends in multimodal machine learning: Principles, challenges, and open questions.” arXiv preprint arXiv:2209.03430 (2022).
[2]Baltrušaitis, T., Ahuja, C., & Morency, L. P. (2018). Multimodal Machine Learning: A Survey and Taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence.
[3]Zi-Yi Dou, Yichong Xu, Zhe Gan, Jianfeng Wang, Shuohang Wang, Lijuan Wang, Chenguang Zhu, Pengchuan Zhang, Lu Yuan, Nanyun Peng, Zicheng Liu, and Michael Zeng. An empirical study of training end-to-end vision-and-language transformers, 2021
[4] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021.
[5]Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation, 2021
[6]Huang, Wenke, et al. “Keeping yourself is important in downstream tuning multimodal large language model.” arXiv preprint arXiv:2503.04543 (2025).
[7]Huang, Wenke, et al. “Learn from Downstream and Be Yourself in Multimodal Large Language Model Fine-Tuning.” arXiv preprint arXiv:2411.10928 (2024).
[8]Liang, Jian, et al. “Lorasculpt: Sculpting lora for harmonizing general and specialized knowledge in multimodal large language models.” arXiv preprint arXiv:2503.16843 (2025).