Abstract
本文介绍了我在联邦学习方面的最新实验研究,重点关注攻击(后门攻击)和防御策略(IQR 过滤与 ClipAvg)。
This article presents my recent experimental research in federated learning, focusing on attacks(Backdoor Attack) and defense strategies(IQR Filtering and ClipAvg).
Expr
The experiments were conducted using the CIFAR-10 dataset, initially employing the FedAvg algorithm as the foundational framework. In subsequent steps, The study simulated a malicious attack scenario: assuming hackers compromised partial client devices, these devices inserted a rectangular pixel block with specific RGB values as a trigger pattern during local training. This manipulation caused all marked images to be misclassified as “dog”. Simultaneously, these malicious clients intentionally amplified the weights of poisoned parameters. When model updates were transmitted to the central server, this carefully designed attack could leverage the parameter averaging mechanism to propagate the attack throughout the system.
for k in range(int(self.conf["batch_size"] * self.conf["alpha"])):
# print(self.conf["alpha"])
if k < len(data):
img = data[k].numpy().copy()
for i in range(len(pos)):
img[0][pos[i][0]][pos[i][1]] = 1.0
img[1][pos[i][0]][pos[i][1]] = 0.0
img[2][pos[i][0]][pos[i][1]] = 0.0As anticipated, malicious clients’ attack corrupted the global model, inducing deterministic responses to backdoor triggers. However, the attack’s amplified parameter updates enabled straightforward detection. To mitigate this, the study implemented a defense mechanism based on Euclidean distance analysis and interquartile range (IQR) filtering. Post-aggregation, the server computed pairwise Euclidean distances between client updates and excluded outliers via IQR thresholds. Empirical results demonstrated that undefended models suffered catastrophic convergence failure under attack, whereas IQR-filtered models retained stable convergence trajectories.
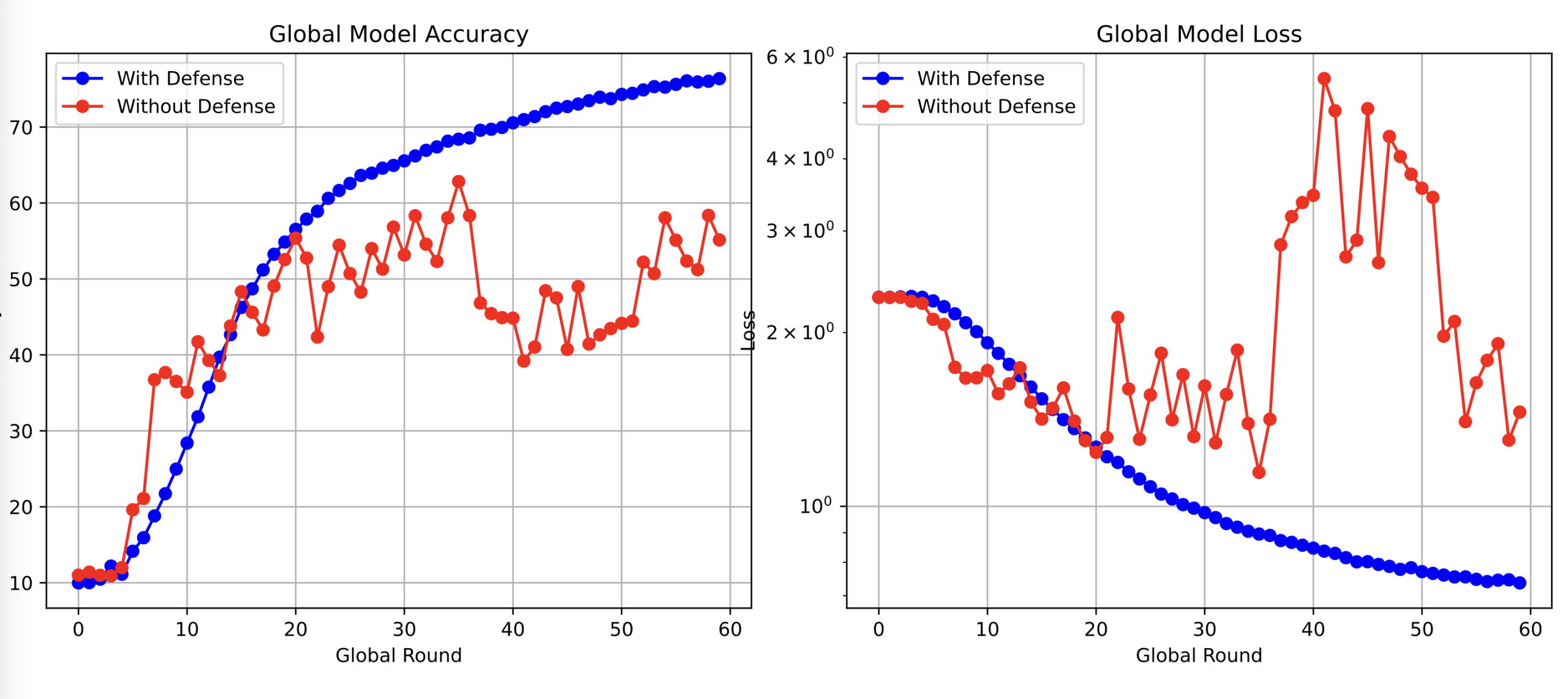
A critical limitation emerged the amplified attack strategy exhibited excessive detectability. To address this, the study refined the attack by introducing a poisoning ratio parameter, α, which controls the proportion of trigger-embedded samples within malicious clients’ local datasets. When α=0, the system operates in FedAvg mode. As α increases, attack efficacy improves at the cost of reduced stealth.
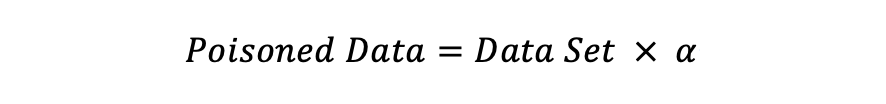
Traditional metrics (e.g., loss, accuracy) proved insufficient for evaluating backdoor success; thus, the study proposed Success Rate (SR), defined as the percentage of poisoned test samples misclassified as the target label. A baseline SR of ~10% (random guessing) indicates no attack, while SR approaching 100% signifies full compromise.
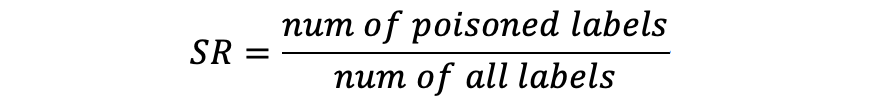
Systematic experimentation across varying α values revealed distinct behavioral regimes. At α=0, SR remained near baseline levels. Gradual increases in α induced progressive SR escalation during later training phases. However, excessively high α values triggered pronounced fluctuations in global accuracy and loss, rendering attacks detectable via IQR.
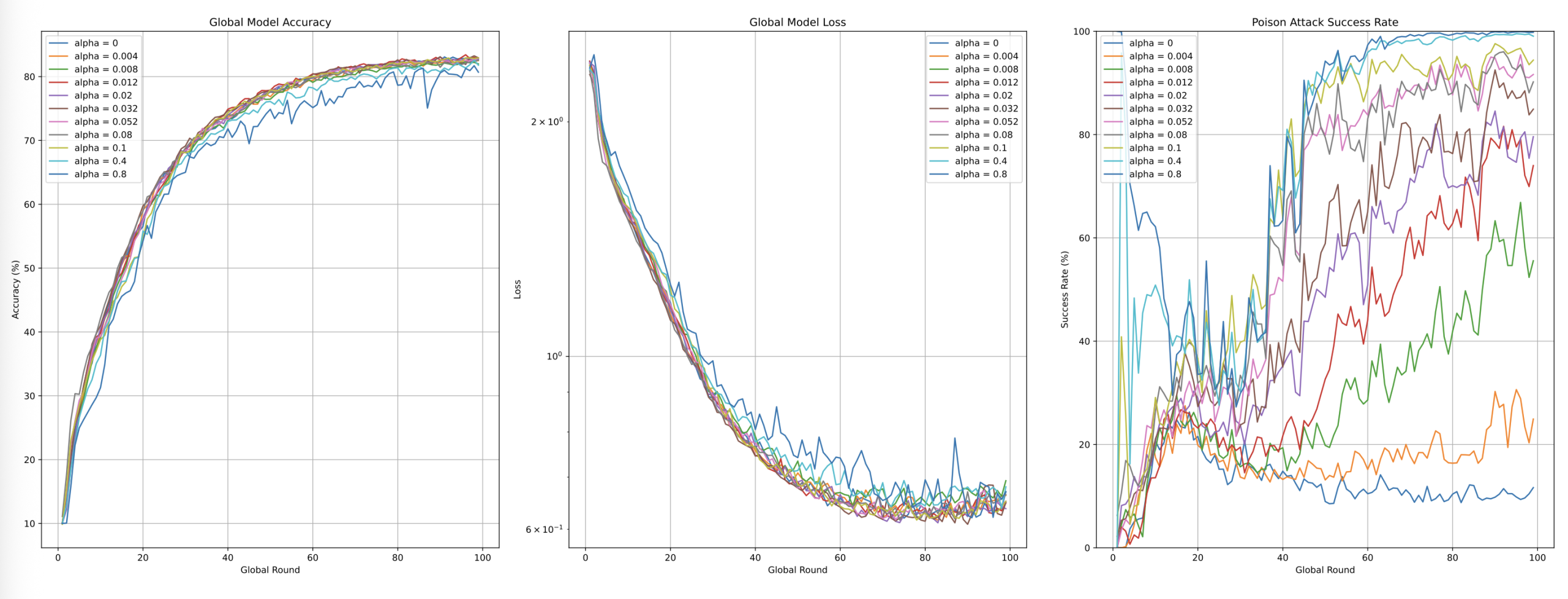
To balance efficacy and stealth,α=0.052 was chosen. (empirically derived from SR-α curves), which achieved near-maximal SR (~100%) without inducing detectable anomalies—unlike higher α regimes (e.g. “over-aggressive” α=0.1)
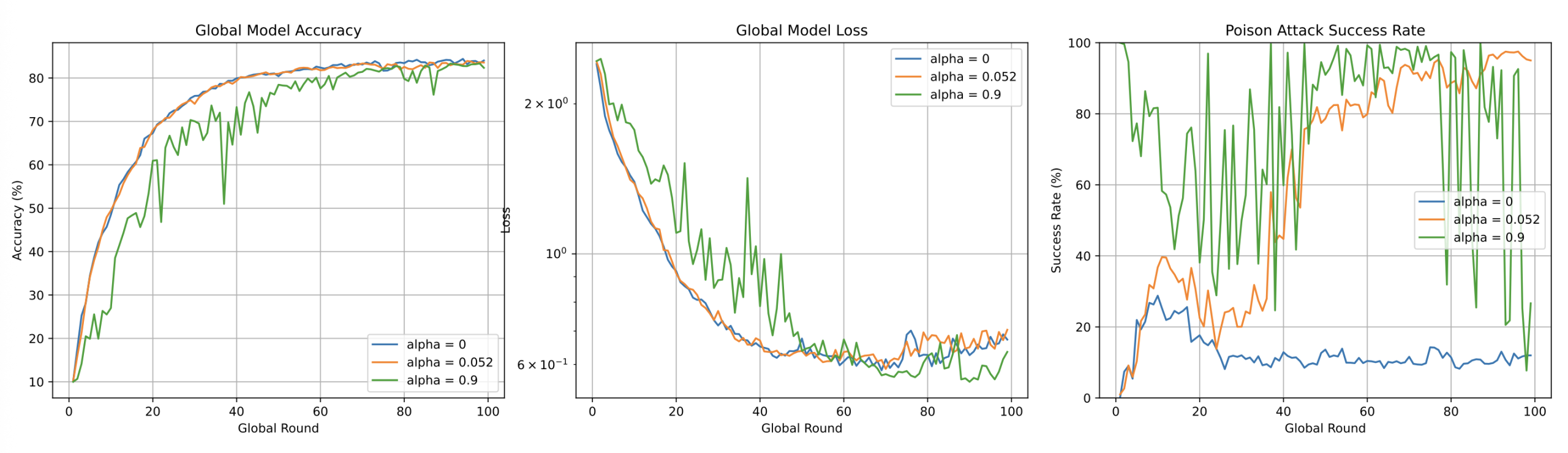
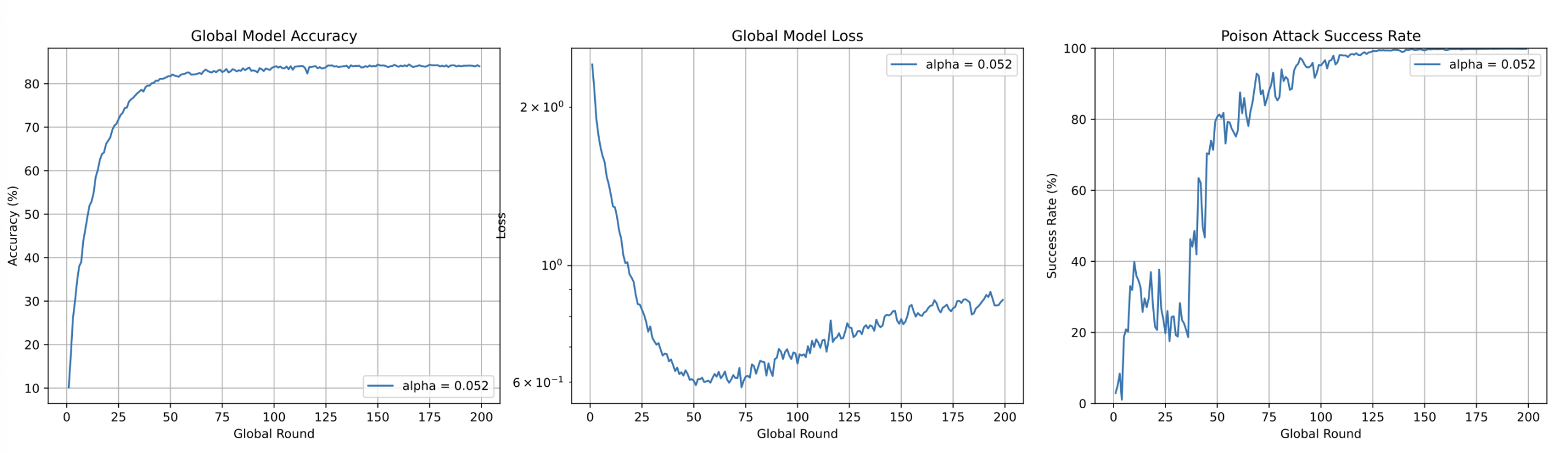
Malicious clients’ stealth-optimized attacks rendered IQR defense ineffective, as aggressive filtering risked excluding legitimate clients. To address this, Clip Averaging strategy was adopted, which dynamically thresholds gradient magnitudes during aggregation. Early training phases employ relaxed clipping (threshold=1.0) to preserve convergence speed, while progressively tightening thresholds suppress anomalous updates in later phases.
def Clip_Avg(self, client_diffs, global_round, T):
gamma_t = self.conf["clip_gamma"] * (global_round + 1) ** (-self.conf["clip_decay"])
lr = self.conf["lr"]
keys = self.global_model.state_dict().keys()
clipped_grads = []
norm_list = []
norm_listcpu = []
g_avg_list = []
for diff in client_diffs:
g_avg = {}
for key in keys:
g_avg[key] = diff[key] / (-lr * T)
total_norm = 0.0
for key in keys:
param_grad = g_avg[key].to(torch.float32)
total_norm += torch.norm(param_grad, p=2) ** 2
total_norm = torch.sqrt(total_norm)
print(total_norm, T)
norm_listcpu.append(total_norm.cpu().item())
norm_list.append(total_norm)
g_avg_list.append(g_avg)
lowb, upb = detect_lower_outliers_iqr(norm_listcpu, 0.3)
for i in range(len(client_diffs)):
if norm_list[i] > upb:
clip_coef = min(1.0, gamma_t / (total_norm + 1e-10))
print("clip:")
else:
clip_coef = 1
print(i, clip_coef, gamma_t / (total_norm + 1e-10))
clipped_grad = {}
for key in keys:
clipped_grad[key] = g_avg_list[i][key] * clip_coef
clipped_grads.append(clipped_grad)
avg_grad = {}
for key in keys:
avg_grad[key] = torch.zeros_like(self.global_model.state_dict()[key])
for grad in clipped_grads:
avg_grad[key] += grad[key].to(avg_grad[key].dtype)
avg_grad[key] = (avg_grad[key] / len(clipped_grads)).to(avg_grad[key].dtype)
for key, param in self.global_model.state_dict().items():
update = (avg_grad[key] * self.conf["lambda"] * (-lr * T)).to(avg_grad[key].dtype)
param.add_(update)Post-implementation, SR plateaued at ~80%, a significant reduction from the original 100%. Nevertheless, subtle gradient perturbations in stealthy attacks limited detection sensitivity.
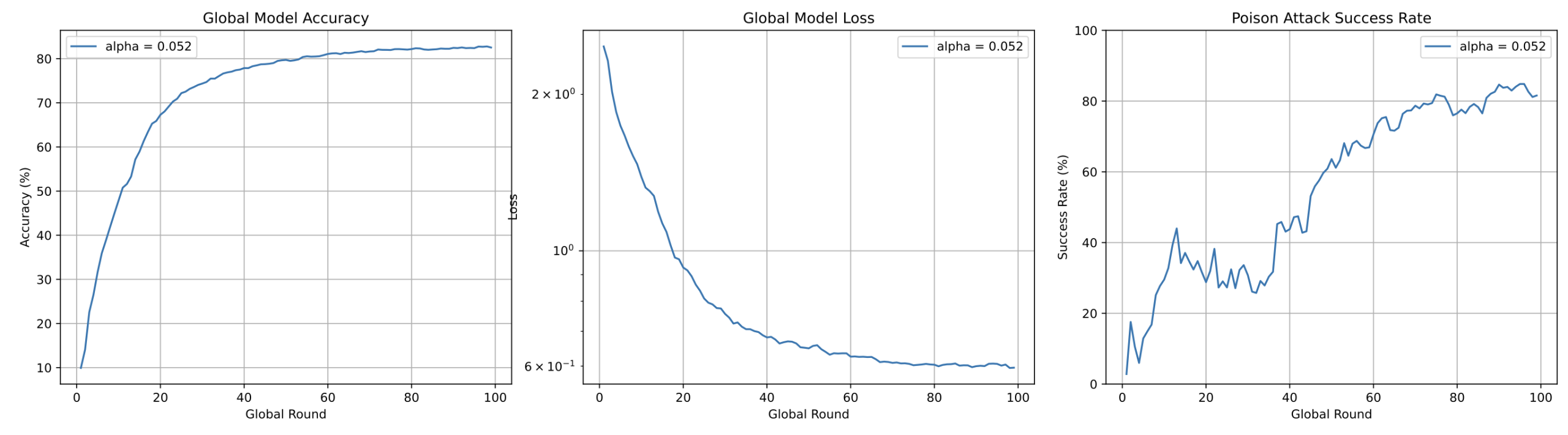
To further enhance robustness, the study integrated high-sensitivity IQR monitoring with gradient clipping. Suspicious updates identified by IQR underwent amplified clipping coefficients. This hybrid approach suppressed SR to ~50% even under minimal-α attacks—a stark contrast to undefended models (SR=100%).
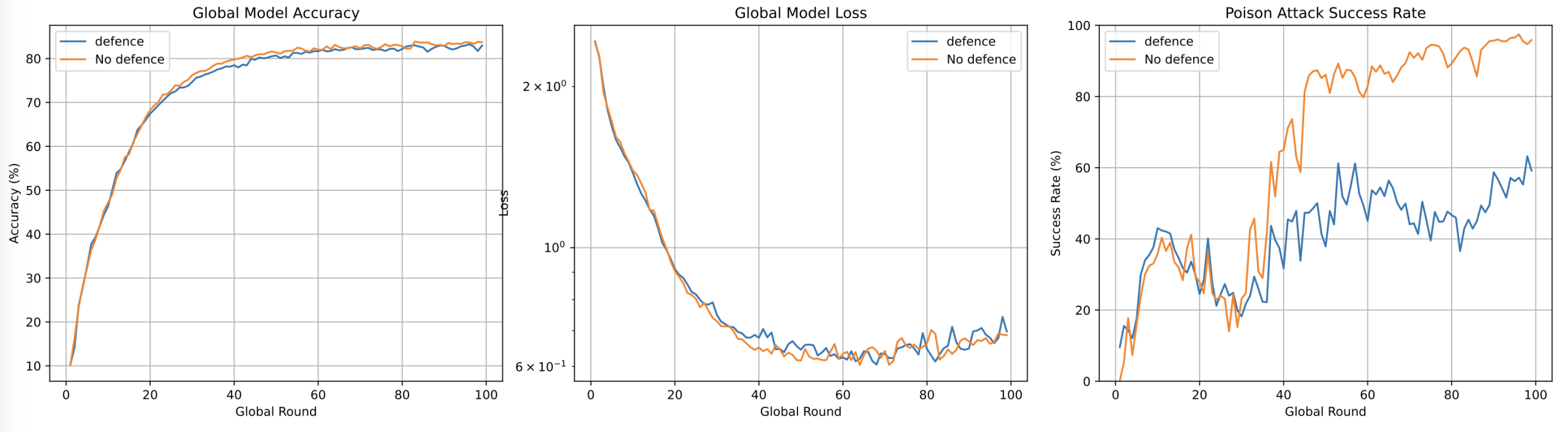
Notably, the defense-maintained convergence speed and neutralized high-intensity attacks, reducing SR to near-baseline levels (~12%).
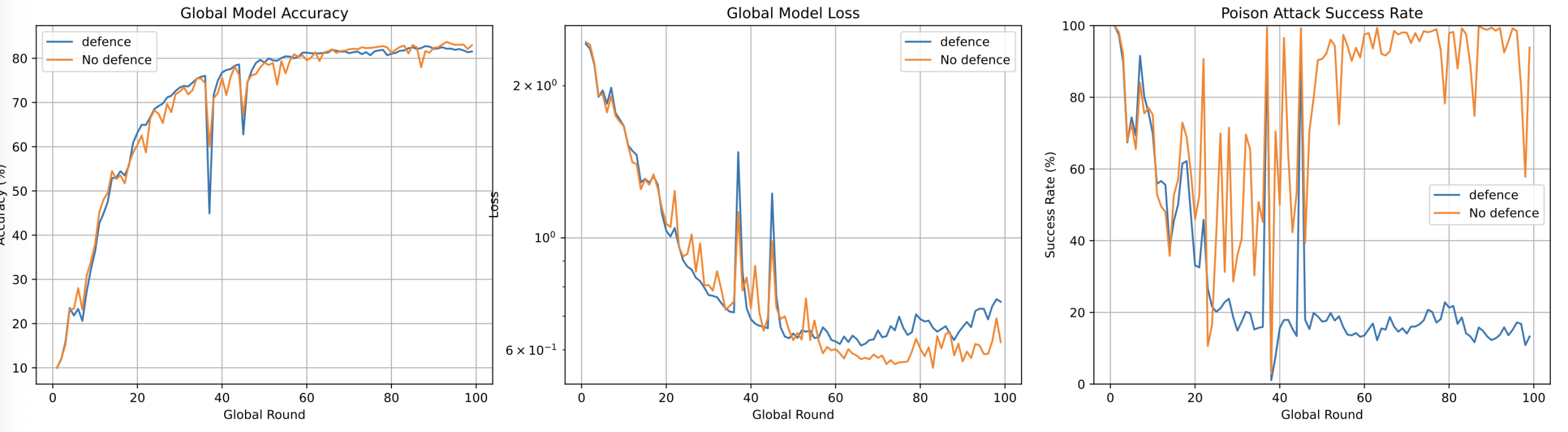
This study still has several methodological limitations: First, due to time constraints, experiments under non-independent and identically distributed (Non-IID) data scenarios were not implemented, which may raise questions about the applicability of current conclusions in real-world heterogeneous data environments. Second, the experimental design was confined to the CIFAR-10 dataset with a single fixed trigger pattern (rectangular RGB trigger blocks), failing to comprehensively validate the generalization capability of the attack method across multimodal data and dynamic trigger mechanisms.