🎉 这篇实在是太经典了
作者单位
Google Research
论文背景和问题
Transformer模型架构已经在语言领域发光发热,有非常良好的性质(训练效率高,可以通过注意力机制来理解复杂语义,且结构简单,可以自由拓展模型大小,千亿级参数下都没有出现性能饱和,潜力极大)早在这篇论文之前,有许多人做过将CV结合上注意力机制[1][2],但要么就是规模太小性能不好,要么就是修改了transformer的机制。因此,对于原版transformer的在CV领域的通用性迫在眉睫。
论文动机和贡献解读
验证了在不对transformer做任何修改的情况下,解决CV问题的可行性;
研究了在不同大小的数据集上,Transformer和卷积神经网络之间的性能对比;
方案设计分析
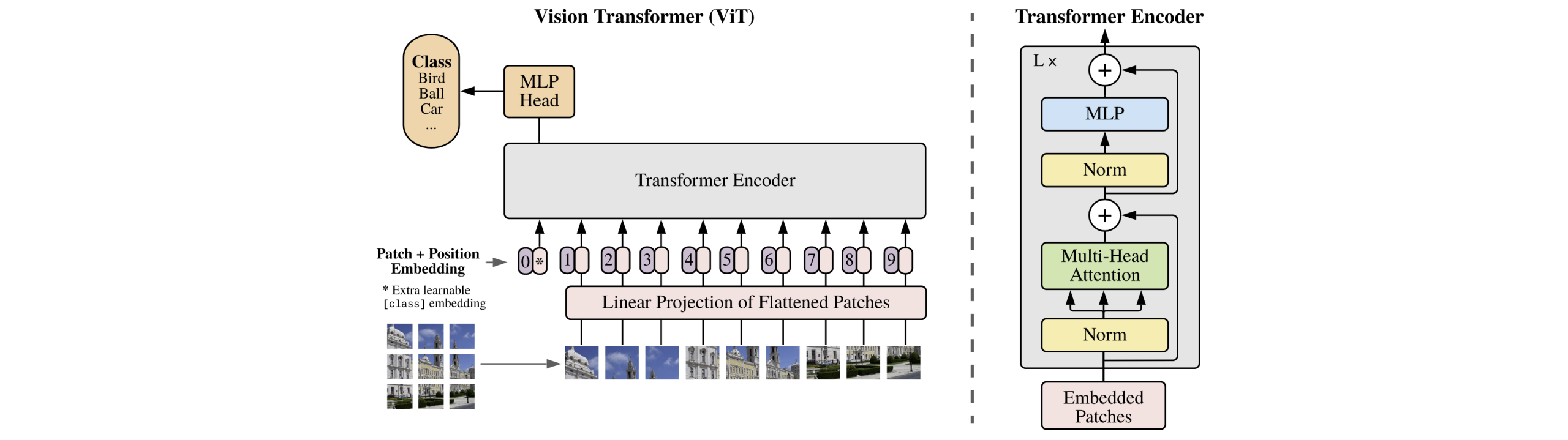
本文的天才想法是,首先将一个图片按照固定大小分成一个一个patch(原文中是16*16,这个地方其实可以理解为创立若干个16 *16的卷积核,其步长也为16,padding为valid),再将其展平后带入一个Linear层进行embedding。
然后再给每个位置,加上一个可学习的位置编码。再在最前面加上一个用于分类的token(当然这里使用的是encoder架构,也就是没有mask,序列中任何位置的token都能看到所有token,所以输出token放在开头是没有问题的)
最后,给第一个分类token加上一个MLP的头,进行分类。
实验效果
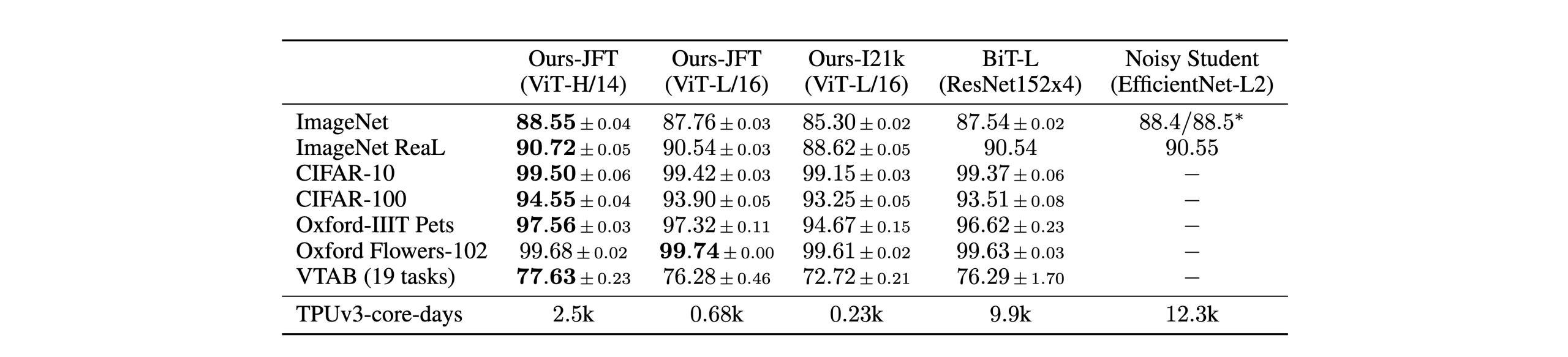
这里作者采取了当时在不同数据集上表现最好的分类模型(ResNet和EfficientNet)进行比较,可以看到ViT-H/14基本取得了更好的结果。
且最后一行说明,Vit模型具有较高的计算效率优势。
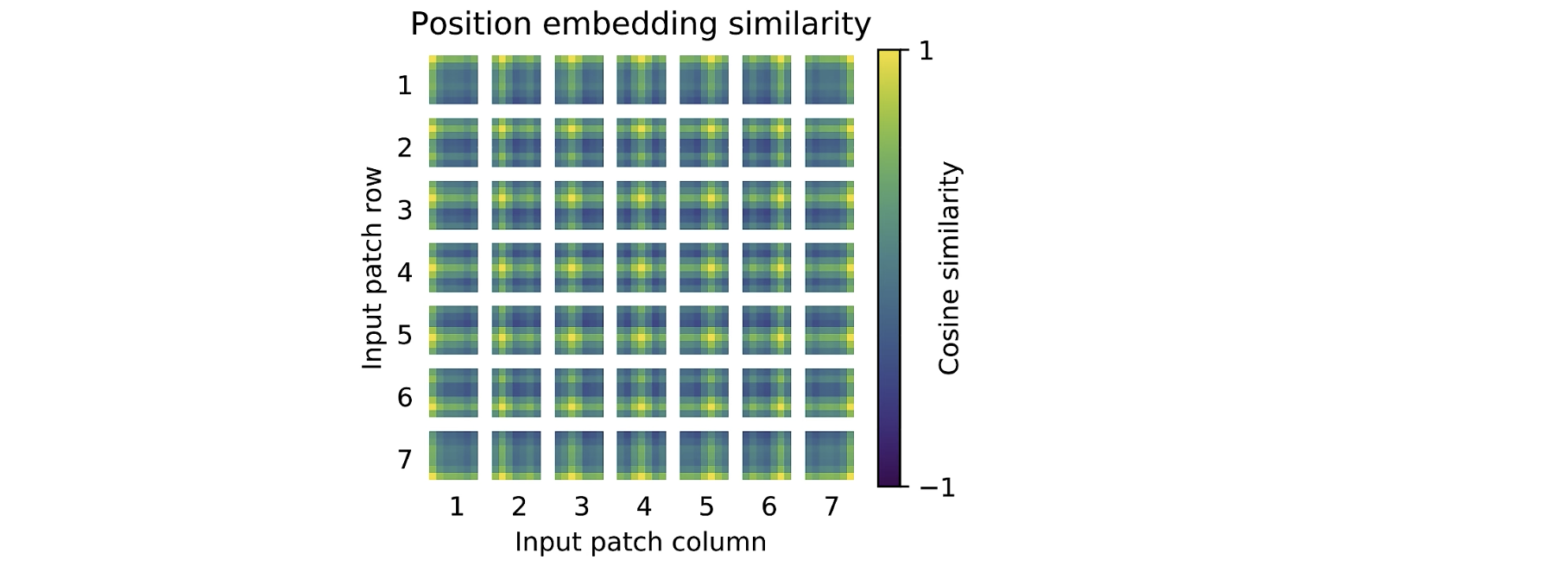
接下来,作者又对位置编码进行了尝试(分为1-D和2-D两种位置编码,1-D即展平,2-D即按行按列进行分割)

可以看到没有位置编码的效果是最差的,其他的1-D 2-D和相对位置编码都差不多。
这里作者进行了更深入的研究,为什么1-D 2-D差不多,是因为实际上1-D也能够在不断的训练中包含二维的位置信息:
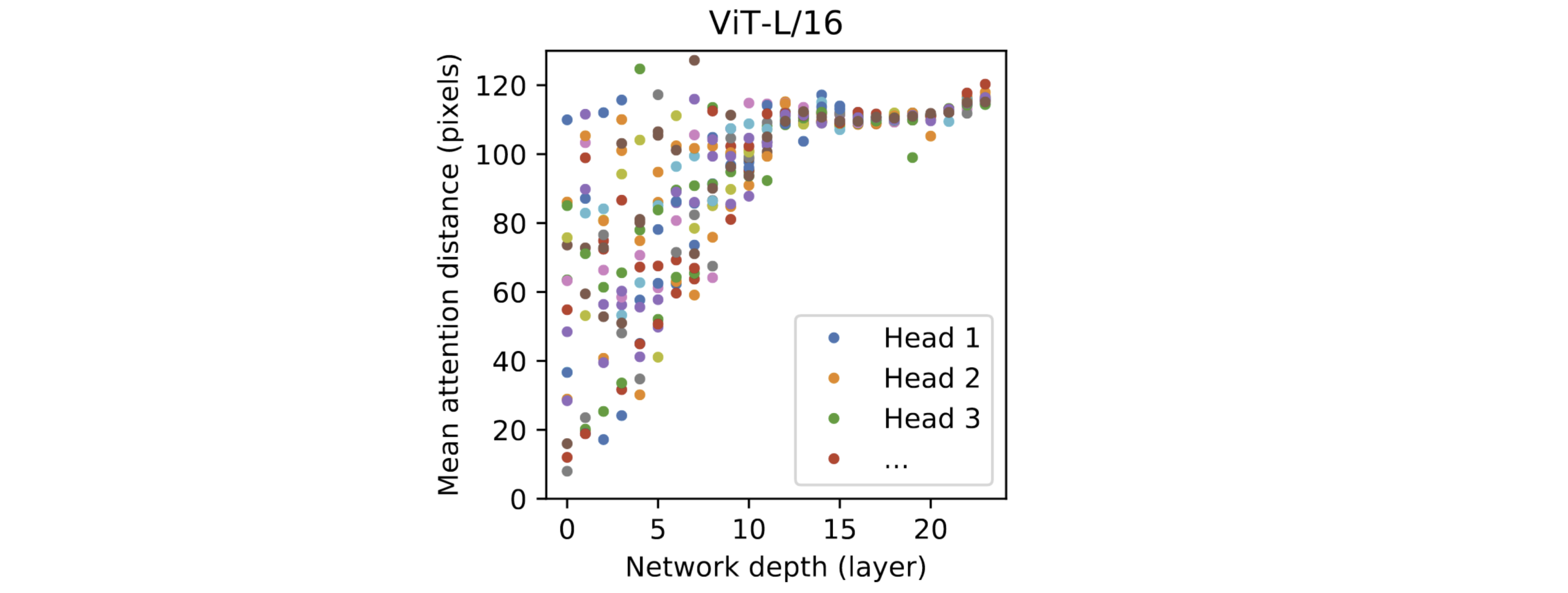
此外,作者还研究了头在不同深度下的表现,可以看到在浅层,部分头关注近距离的像素,部分关注远端像素;而到了深层网络则基本开始关注远端像素了(全局信息)。
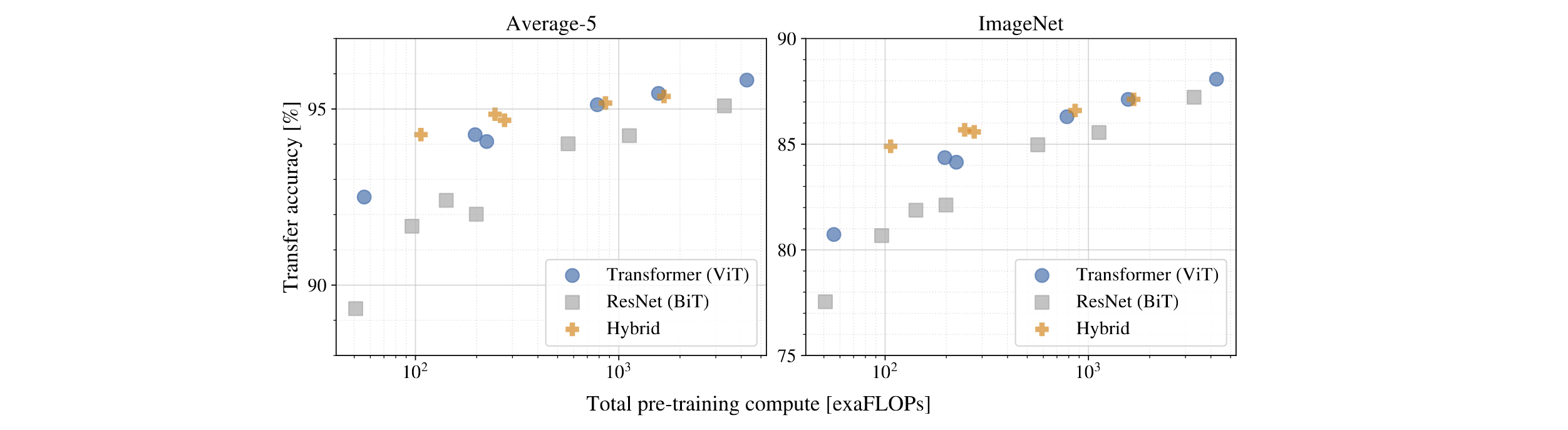
对于模型结构的尝试,作者选择了三种:纯CNN,纯Transformer,两者结合。可以看到,在相同的预训练代价下,刚开始混合模型会存在优势,但是随着预训练代价的增加,可以看到Transformer还是更优的
接下来,作者研究了数据集大小对模型的影响:
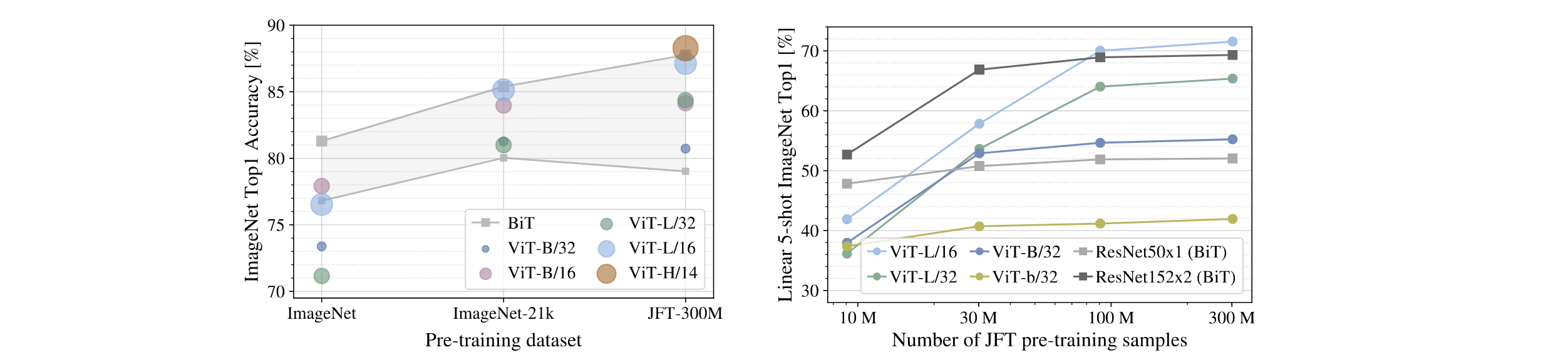
可以看到在小规模数据集上ResNet更优秀,而ViT则在更大的数据集上优于ResNet。
结论
- transformer模型可以不做任何修改来解决计算机视觉问题。
- 小规模数据集上表现略逊于卷积神经网络,而在中等和大规模数据集上的表现相当或优于卷积神经网络。
- 在计算效率上,训练同等精度的模型,Transformer模型比卷积模型更有优势。
理解
这篇文章的引用已经接近60k了,我觉得他厉害的点在于证明Transformer的通用性,这为后面的基于Transformer的多模态大模型铺平了道路,而且这种通用性,也让Transformer的一些优化,例如Flash Attention[3] vLLM[4]等,能够直接应用在包含CV的多模态领域。
参考文献
[1]Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In CVPR, 2018.
[2]Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jon Shlens. Stand-alone self-attention in vision models. In NeurIPS, 2019.
[3]Dao, Tri. “Flashattention-2: Faster attention with better parallelism and work partitioning.” arXiv preprint arXiv:2307.08691 (2023).
[4]Kwon, Woosuk, et al. “vllm: Easy, fast, and cheap llm serving with pagedattention.” See https://vllm. ai/(accessed 9 August 2023) (2023).